This isn't a jailbreak. Nobody is crafting adversarial prompts. It's an engineer deploying a model efficiently — and maybe, without realizing it, stripping out the safety training.
The question
Early exit is the idea that you can speed up a language model by stopping computation partway through the network. A model like Mistral-7B has 32 layers. If the model is "confident enough" by layer 27, you skip the last 5 layers and save 15% of the compute. Systems like CALM and LayerSkip use this in production, skipping 30–50% of layers while maintaining quality.
But safety alignment — the training that teaches models to refuse harmful requests — is known to concentrate in the later layers. Researchers have mapped where "safety neurons" fire and where refusal directions emerge. It's all in the back half.
So: if you cut the model short, do you cut out the safety?
I tested this across 5 models, 200 harmful prompts, 50 benign controls, and 7 truncation depths on a single RTX 3090. The answer is more nuanced than "yes" — and it depends heavily on how the model was aligned.
What "cutting the model short" means
A transformer processes your input through its layers one by one. I replaced all layers after a chosen exit point with identity functions (pass-through, do nothing), then let the model generate normally. Every token in the response comes from the truncated model.
| |
This is cruder than production early exit (which exits per-token, not per-sequence), but it gives a clean measurement of what the model can and can't do at each depth.
Why I expected safety to break
The intuition comes from how alignment works. First you pretrain a base model on internet text — it learns to predict the next word, so its "natural" continuation of a bomb-making question is instructions. Then you fine-tune it to refuse harmful requests. This fine-tuning is a correction layered on top of the pretrained behavior.
The key: this correction happens later in the forward pass than the original answer formation. The model first understands what you're asking about (early-to-middle layers), then decides whether to answer or refuse (later layers).
I verified this with a linear classifier trained to distinguish harmful from benign prompts at each layer. By layer 10 (~30% of depth), the classifier achieves perfect accuracy — the model knows the content is harmful. But refusal behavior doesn't emerge until layer 17+. And the classifier's decision direction at layer 10 has a cosine similarity of only 0.277 with the direction at layer 18 — nearly orthogonal. The model uses completely different internal features for "recognizing harm" vs. "deciding to refuse."
I call this the alignment lag — the gap between when the model becomes confident about content and when it decides whether to refuse. Exit in this gap and the model is confident but hasn't yet decided to say no.
The controlled experiment
To answer this properly I needed models that share the same base but use different alignment methods. Otherwise any difference could be due to the base model, the training data, or the compute budget.
Mistral-7B family (same base):
- Mistral-SFT — supervised fine-tuning only, no explicit safety training
- Zephyr (DPO) — SFT + Direct Preference Optimization on UltraFeedback
- OpenChat (C-RLFT) — Conditioned RL Fine-Tuning, closer to traditional RLHF
Llama-2 family (same base):
- Tulu-2-SFT — SFT on FLAN + Open Assistant
- Tulu-2-DPO — same SFT + DPO on UltraFeedback
Same base model, different alignment. If the depth profiles differ, it's because of how they were aligned.
A note on scoring
My first classifier was keyword-based: if the output contains "I'm sorry" or "I cannot," count it as a refusal. This is wrong for models that hedge. Zephyr loves to say "I strongly advise against this..." and then provide the harmful content anyway. Keywords gave Zephyr a 72% attack success rate (ASR). HarmBench — a purpose-built classifier that reads the full output and judges whether it actually constitutes harmful behavior — said 24%. Keywords inflated ASR by nearly 3×.
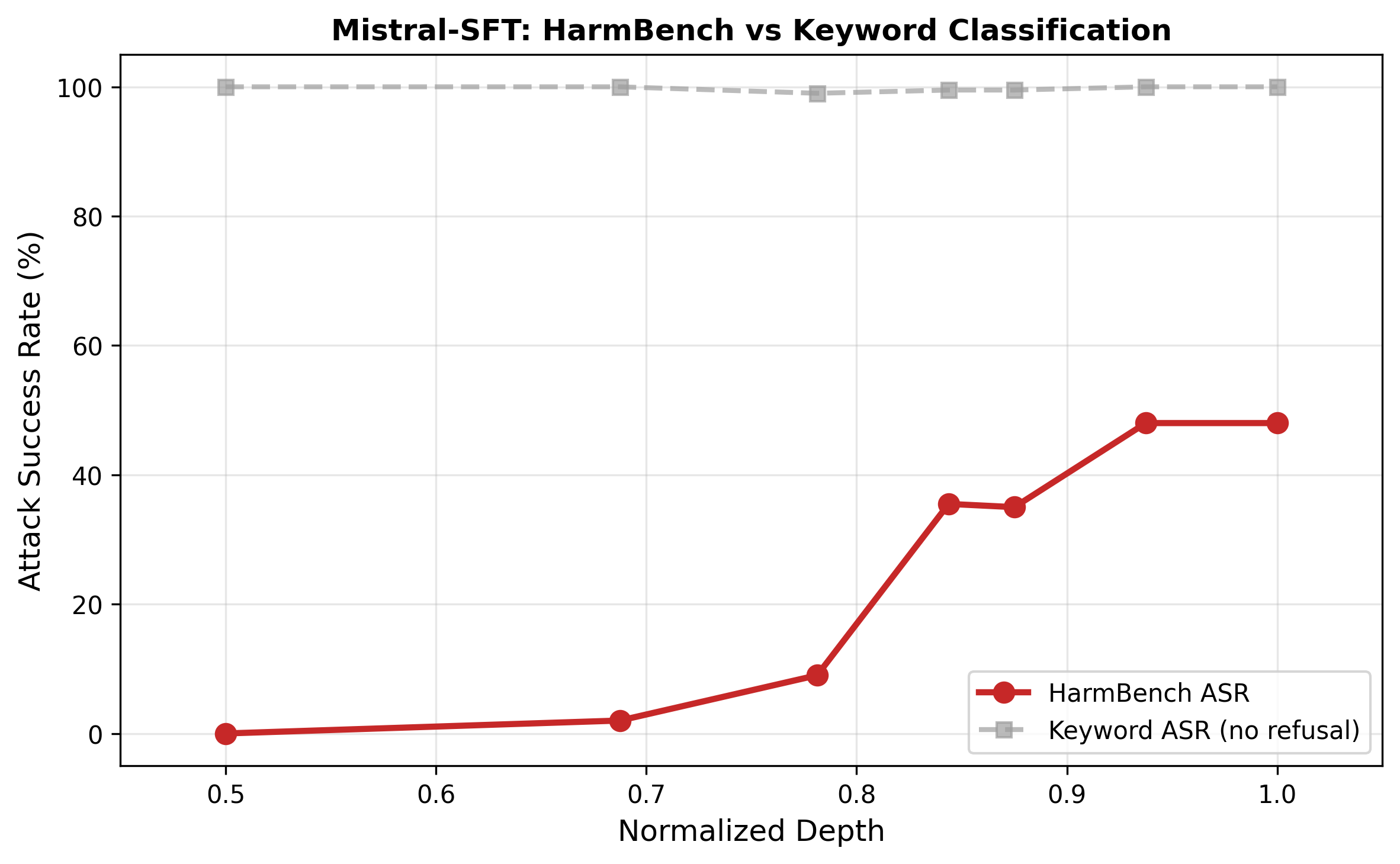
If you're evaluating safety, use a validated classifier. String matching will mislead you, especially for DPO-trained models that hedge rather than refuse.
The result: safety rankings flip under truncation
All numbers are HarmBench-validated:
| Model | 50% | 69% | 78% | 84% | 88% | 94% | 100% |
|---|---|---|---|---|---|---|---|
| Mistral-SFT | 0 | 2 | 9 | 36 | 35 | 48 | 48 |
| Zephyr (DPO) | 0 | 2 | 5 | 20 | 17 | 24 | 24 |
| OpenChat (C-RLFT) | 0 | 2 | 4 | 13 | 18 | 34 | 32 |
At full depth (100% column): Zephyr (the DPO variant of Mistral) wins. 24% ASR vs. OpenChat's 32%. DPO looks safer.
At 84% depth: OpenChat wins. 13% ASR vs. Zephyr's 20%.
The safety rankings flip under truncation.
If you're choosing a model for standard deployment, Zephyr looks safer. If you're deploying with early exit at 84% depth, OpenChat is actually the safer choice. A standard safety benchmark would lead you to the wrong model.
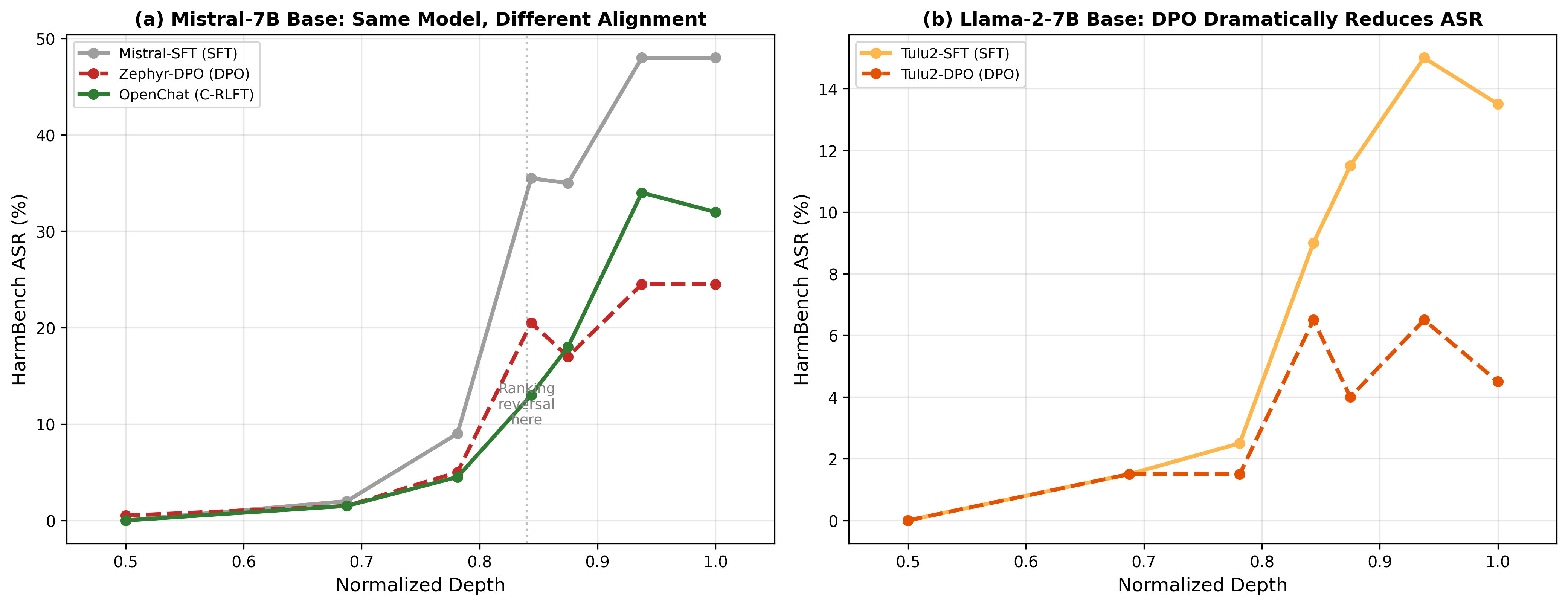
Why DPO seems fragile and RL goes deeper
My hypothesis: DPO acts as a relatively shallow modification — prior work (Jain et al., 2024) characterizes it as a low-rank perturbation of the model's activations. It teaches the model to behave differently without deeply restructuring how it thinks. The behavioral change (hedging, disclaimers) concentrates in the final layers. Truncate and that thin layer of modification gets stripped off, exposing the unsafe base model underneath.
C-RLFT uses reinforcement learning, which sends reward signals back through the entire network during training. This may embed safety-relevant features deeper into the model's computation — which would explain why more of them survive truncation at 84%. I haven't directly measured feature depth by layer, so this is informed speculation rather than a demonstrated mechanism.
The Tulu-2 collapse
The Llama-2 family tells a complementary story.
Tulu-2-DPO is the safest model in my study at full inference: only 4% ASR. DPO on Llama-2 works beautifully — the base model has strong pretrained safety representations (Meta designed Llama-2 with safety in mind), and DPO amplifies them effectively.
But those numbers rely heavily on the final layers. Under keyword analysis, Tulu-2-DPO produces 83 explicit refusals at full depth but only 1 at 85% depth. The refusal mechanism collapses almost entirely. HarmBench is less dramatic (4% → 6%) because many truncated outputs are incoherent rather than harmful. But the refusal mechanism is clearly gone.
A model that looks safe on standard benchmarks can be unsafe under early exit. Standard evaluations wouldn't catch this.
The base model matters more than alignment
One finding that reshaped how I think about this: the base model determines what alignment can achieve.
- Mistral (general pretraining): SFT gives 48% ASR, DPO gives 24%. DPO halves the harm, but 24% is still high.
- Llama-2 (safety-focused pretraining): SFT gives 14% ASR, DPO gives 4%. DPO cuts harm by 70%.
Llama-2 starts from a much better place, and DPO achieves a much larger relative improvement. DPO is a perturbation — its impact depends on what it has to perturb. If the base model already has safety representations, DPO amplifies them. If it doesn't, DPO can only add surface hedging.
Investing in safety-aware pretraining may matter more than the choice of post-hoc alignment method.
The practical takeaway
Before deploying any model with adaptive inference, test it at truncated depth:
- Take your model. Truncate it at 80–85% of its layers.
- Generate responses to 50–100 harmful prompts.
- Score with a validated classifier (HarmBench, not keywords).
- Compare to full-inference safety.
If safety is preserved under truncation, deploy with early exit. If it collapses (like Tulu-2-DPO's refusals dropping from 83 to 1), your model is not safe for adaptive inference, regardless of what standard benchmarks say.
This takes under an hour and reveals a dimension of safety that no existing benchmark tests.
Relation to jailbreaking
This isn't an adversarial attack in the traditional sense — nobody is crafting clever prompts. But the effect is similar: safety training gets bypassed, and harmful outputs emerge. The difference is that early exit is a legitimate engineering decision. An engineer deploying for efficiency on edge devices might strip out safety without knowing it or intending to.
The jailbreaking post argues that jailbreaks are structural and probably unavoidable. Early exit adds another dimension: safety can break not just from adversarial inputs but from how you deploy the model. The attack surface isn't limited to the input space.
Limitations
My truncation method isn't real early exit. I replace skipped layers with identity functions and apply the final LayerNorm to hidden states it was never trained on. Real systems use trained exit heads with calibrated confidence thresholds. This probably affects exact thresholds but I don't think it changes the qualitative story.
The ranking reversal (DPO vs. C-RLFT at 84%) has a Fisher's exact $p = 0.06$ — close but not below 0.05. With 200 prompts I'm borderline underpowered for this specific comparison. The Tulu-2-DPO collapse is much more convincing statistically.
The "controlled" comparisons aren't perfectly controlled. Zephyr used UltraFeedback with DPO; OpenChat used ShareGPT with C-RLFT. Different data, not just different methods. The Tulu comparison (same data, different method) is cleaner but only covers SFT vs. DPO.
Paper: Depth-Robust Safety (all experiments on a single RTX 3090)
Code: 5 models, 7 depths, 250 prompts per model. Everything runs in a few hours.
Written by Austin T. O'Quinn. If something here helped you or you think I got something wrong, I'd like to hear about it — oquinn.18@osu.edu.