This post is about a paradox in safe reinforcement learning: the better your safety mechanism works during training, the less safe the trained agent might be without it.
What's a safety shield?
In reinforcement learning, an agent takes actions in an environment, receives rewards, and learns a policy — a mapping from situations to actions. The goal is to maximize cumulative reward. The problem is that during training (and sometimes after), the agent might do dangerous things.
A safety shield is a runtime monitor that sits between the agent and the environment. The agent proposes an action. The shield checks: "would this action violate a safety constraint?" If yes, the shield modifies the action to the nearest safe alternative. If no, it passes the action through unchanged. The agent never even knows it was overridden.
The implementation I used is a Control Barrier Function (CBF) — a mathematical function that defines a "safe region" around each hazard. If the agent's proposed action would push it too close to a hazard boundary, the shield projects the action onto the nearest safe trajectory. Minimal intervention, formal guarantee.
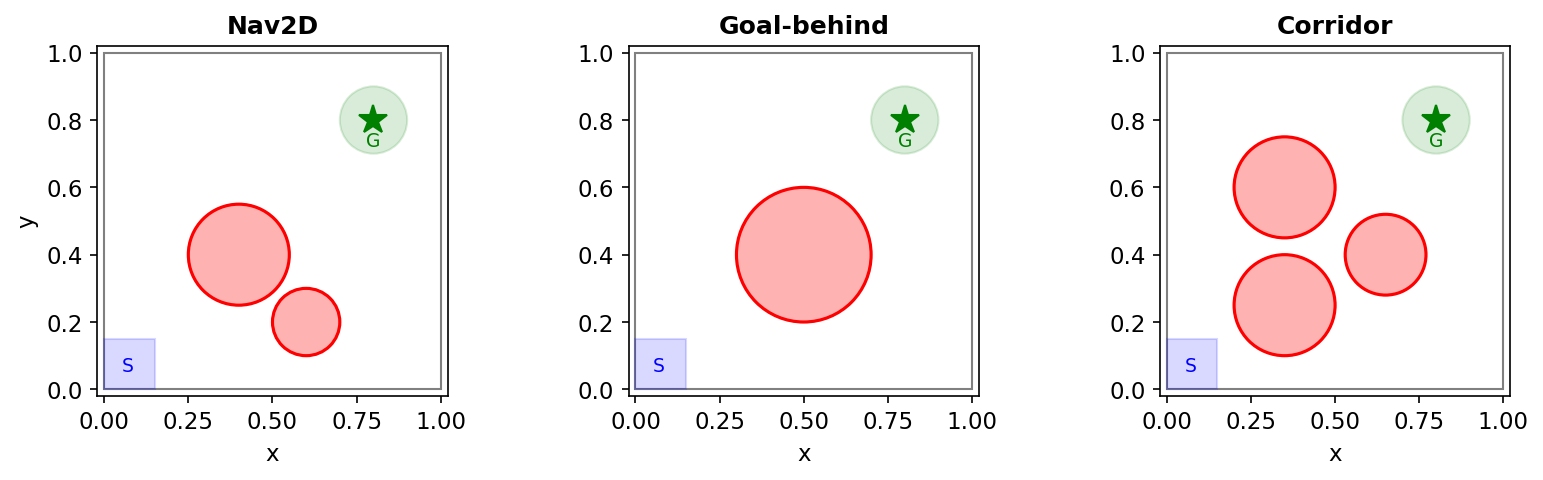
For this experiment, the task is simple: a 2D agent must navigate to a goal while avoiding circular hazard zones. The shield monitors every action and ensures the agent never enters a hazard.
It works perfectly. The system never touches a hazard zone during training.
And that's exactly the problem.
What happens when you remove the shield
The intuition for shielded training is straightforward: the agent trains in a safe environment, so it should internalize safe behavior. The shield is training wheels. Eventually you take them off.
I trained a PPO agent (a standard RL algorithm) under perfect shielding for 100K steps, then evaluated it both with and without the shield. 40 random seeds for statistics.
| How we evaluated | Seeds that learned safe behavior | Goal success rate |
|---|---|---|
| With shield on (the "system") | 40/40 (100%) | 93% |
| Shield removed (raw policy alone) | 20/40 (50%) | — |
| Never used a shield at all | 21/40 (52%) | 85% |
With the shield on, every seed is perfectly safe. Remove the shield, and only 50% of seeds produce safe policies. That's statistically indistinguishable from never having used a shield at all ($p = 1.0$). The shield provided zero benefit to what the agent actually learned.
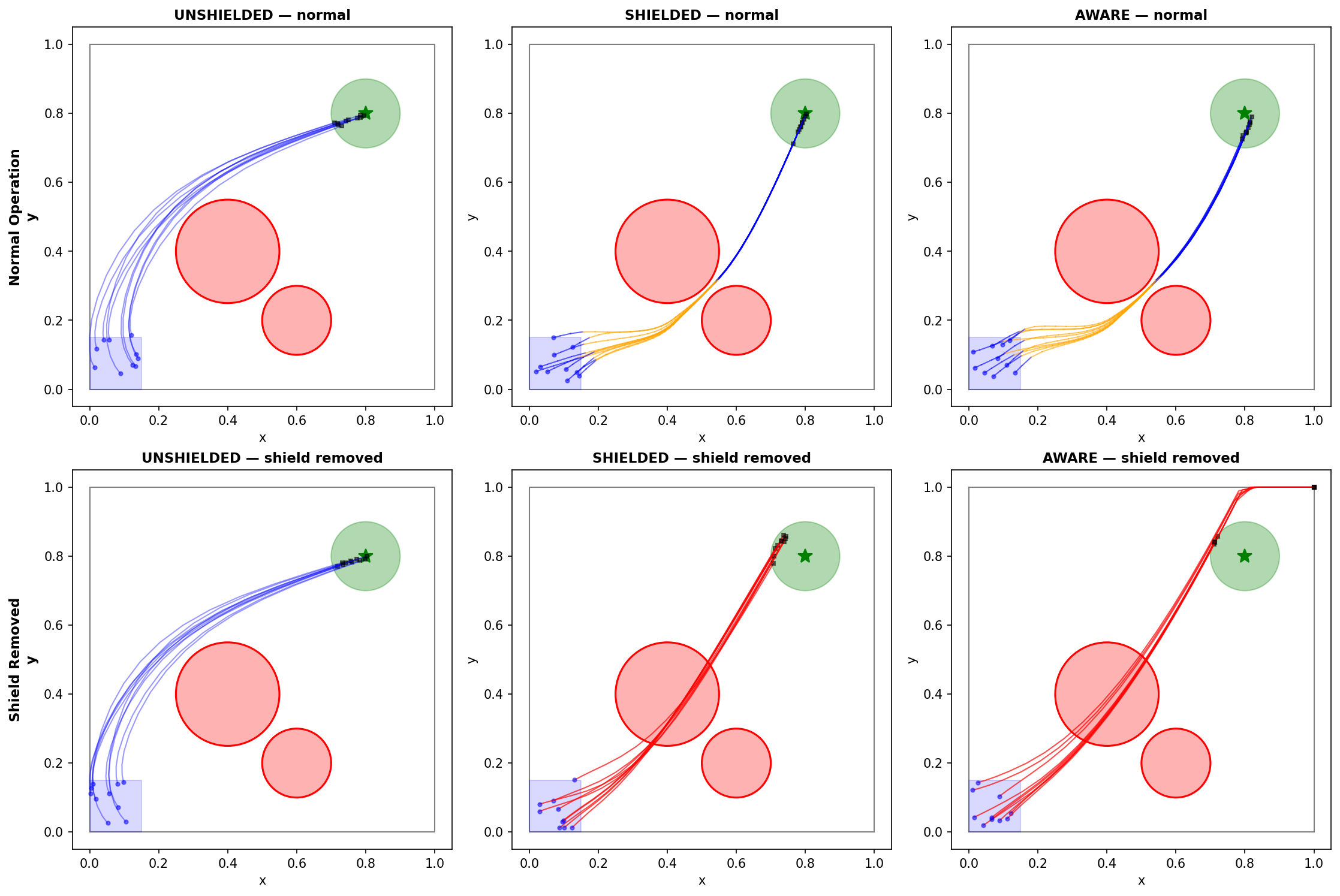
A representative dependent seed shows the problem clearly. The DNN accelerates directly toward the goal, regardless of obstacles. The shield silently corrects 65.8% of its action vectors, steering it around hazards it doesn't even represent internally. The agent is a passenger in its own safety.
Why more penalty doesn't help
The obvious fix: "just make the hazard penalty bigger." Give the agent a really strong reason to avoid dangerous areas.
I swept the penalty from $-0.1$ to $-50$ — a 500× range:
| Hazard penalty | Shielded agent's raw hazard rate | Unshielded agent's hazard rate |
|---|---|---|
| $-0.1$ | 0.50 | 1.00 |
| $-1.0$ | 0.50 | 0.13 |
| $-5.0$ | 0.50 | 0.00 |
| $-10.0$ | 0.50 | 0.00 |
| $-50.0$ | 0.50 | 0.00 |
The unshielded agent responds immediately — by $-5.0$, it's learned to avoid hazards completely. The shielded agent? Constant at 0.50, no matter the penalty. Doesn't budge.
The mechanism is simple once you see it. The shield prevents the agent from entering hazard zones. So the hazard penalty never fires. No penalty means no gradient signal telling the network "don't go there." The shield doesn't just make the penalty unnecessary — it makes it invisible.
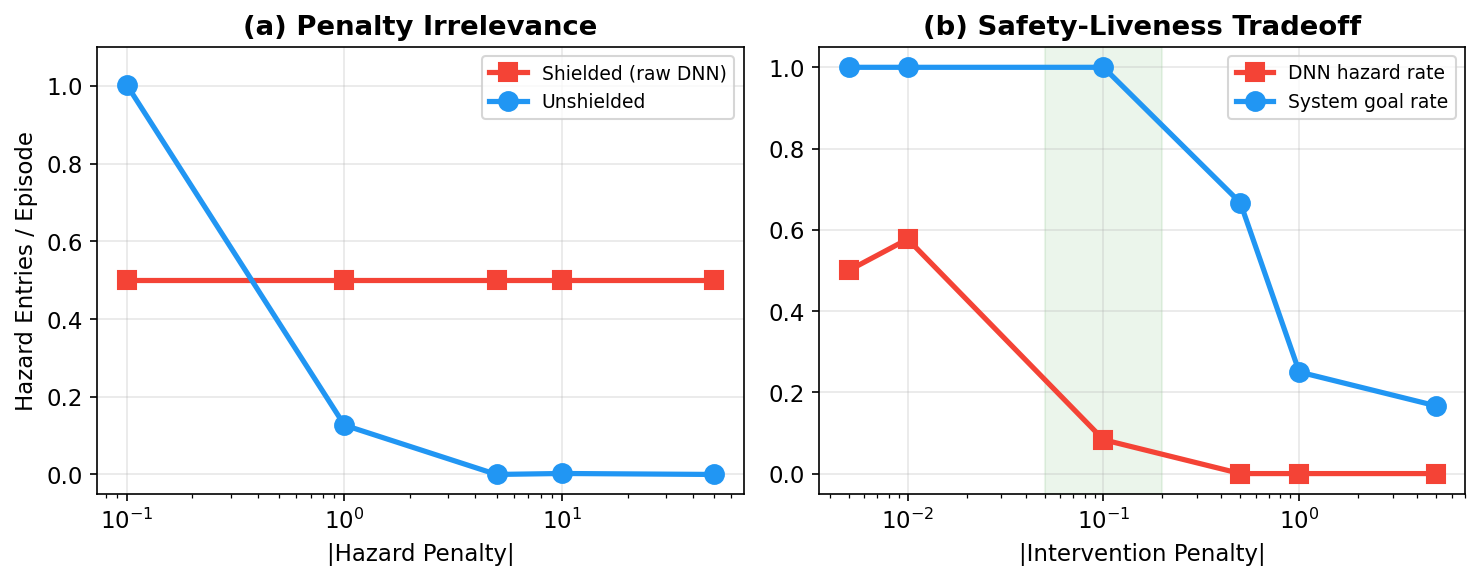
I call this the safety signal barrier. The shield severs the feedback loop between the safety constraint and the learning algorithm. No amount of reward engineering can overcome a barrier that prevents the reward from being experienced. It's not that the agent chooses to ignore safety. It literally never sees the information it would need to learn safety.
Three ways to fix it
Once you understand the barrier as an information flow problem, the fixes become natural. The policy needs some signal about hazards during training. There are three ways to provide it.
1. Shield dropout
The most direct fix: make the shield unreliable on purpose. At each timestep, the shield intervenes with probability $\rho$. When it doesn't intervene (with probability $1 - \rho$), the agent enters the hazard zone, receives the penalty, and updates its weights to avoid that state in the future. When it does intervene, it still protects against the worst outcomes.
Think of it like training wheels that occasionally let you wobble — just enough to learn balance, not enough to crash hard every time.
Implementation: one random number check per timestep. No changes to the reward, architecture, or training algorithm.
2. Auxiliary reward shaping
Keep the shield perfect but sneak the safety signal in through the reward function. I added a continuous penalty based on proximity to hazard boundaries:
$$r_{\text{aux}} = -0.5 \cdot \max(0, 0.2 - m)$$
where $m$ is the distance to the nearest hazard. Plus a small penalty ($-0.05$) whenever the shield actually intervenes. The agent learns that being near a hazard is costly, even though being inside one never happens. The shield stays perfect — zero training-time violations — but the reward carries the safety information that the shield would otherwise block.
3. PPO-Lagrangian (no shield at all)
A constrained RL baseline from the literature: instead of a shield, an adaptive penalty multiplier learns to punish constraint violations. When the agent enters hazards frequently, the penalty grows. When violations are rare, the penalty shrinks. No external safety mechanism — the agent must learn safety entirely from experience.
I included this as a control. If it matches the shield-based solutions, that confirms the diagnosis: the information barrier — not the specific fix — is the core issue.
The results ($n = 40$ seeds, properly powered)
I ran a power analysis beforehand, fixed the analysis plan, and used Bonferroni correction for multiple comparisons. Five conditions:
| Condition | Safe seeds | Training-time violations | Goal rate |
|---|---|---|---|
| Perfect shield ($\rho = 1.0$) | 20/40 (50%) | 0 | 93% |
| Shield dropout ($\rho = 0.5$) | 35/40 (88%) | 73 | 72% |
| Shield dropout ($\rho = 0.3$) | 31/40 (78%) | 136 | 65% |
| Unshielded ($\rho = 0.0$) | 21/40 (52%) | 1,490 | 85% |
| Auxiliary reward | 37/40 (92%) | 0 | 80% |
Shield dropout ($\rho = 0.5$) vs. perfect shield: 35/40 vs. 20/40 safe, $p = 0.00029$, odds ratio = 7.0. That's a strong effect.
Auxiliary reward: 37/40 vs. 20/40, $p = 0.00003$. The best result — highest safety rate (92%), zero training-time violations, 80% goal rate. If you can design the reward, this is the way to go.
All three approaches work. PPO-Lagrangian matches the others. The information barrier is the problem; anything that restores information flow fixes it.
Three different environments
Fair question: maybe this is specific to one layout of hazards. I tested three environments with different hazard geometries ($n = 12$ seeds each):
| Environment | Unshielded | Perfect shield | Dropout | Aux. reward | Lagrangian |
|---|---|---|---|---|---|
| Nav2D (room to maneuver) | 2/12 | 5/12 | 9/12 | 11/12 | 11/12 |
| Goal-behind (hazard blocks path) | 6/12 | 4/12 | 12/12 | 11/12 | 11/12 |
| Corridor (narrow gap) | 9/12 | 3/12 | 12/12 | 12/12 | 12/12 |
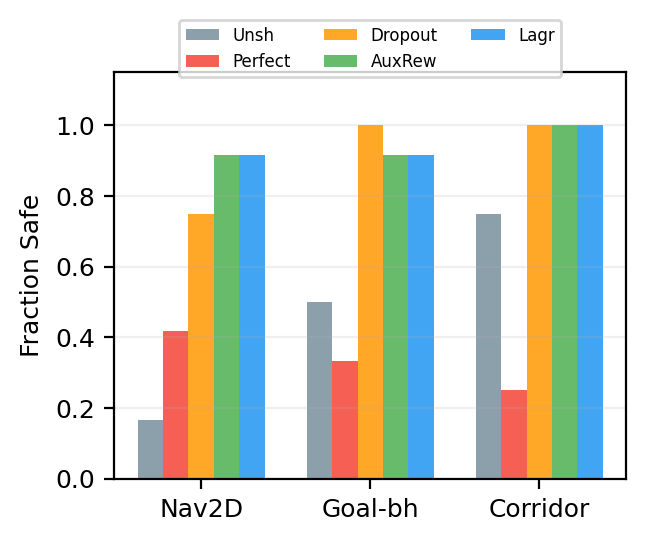
The pattern holds everywhere. All three solutions outperform perfect shielding in every environment ($p \leq 0.005$).
The corridor result is the most striking. Only 3/12 perfectly-shielded seeds are safe without the shield, compared to 9/12 for unshielded training ($p = 0.020$). Perfect shielding is worse than no shield at all. Why? The shield-dependent policy learned to charge through the narrow gap at full speed, relying on the shield to deflect it through. Remove the shield and it crashes. The unshielded agent, forced to navigate on its own during training, developed cautious behavior.
Where this doesn't work
Shield dropout addresses discrete hazard avoidance — "don't enter this region." It doesn't help with continuous, reward-aligned constraints.
I tested on MuJoCo Hopper with a forward velocity constraint ($v_x < 1.5$). Shield dropout produced 100% violation rate, identical to unshielded training. Velocity constraints are different: faster locomotion always earns higher reward, so the policy is always incentivized to push toward the constraint boundary. There's no discrete "unsafe zone" to learn to avoid — just a continuous tradeoff where the reward gradient points toward violation. This is a structural limitation.
The uncomfortable tradeoff
Here's something that complicated my thinking. When evaluated with the shield present, dependent policies are actually better systems:
- Dependent policies (with shield): system reward $8.3 \pm 0.5$, 22 steps to goal
- Independent policies (with shield): system reward $4.6 \pm 6.8$, 62 steps to goal
The shield-dependent policy learned a simpler, more efficient strategy: go straight to the goal and let the shield handle obstacles. That's rational. It produces a better system — faster, more reliable — even though the component (the policy alone) is unsafe.
Among perfectly-shielded seeds, the ones that incidentally learned safety achieve lower system reward ($7.8$) than the ones that stayed fully dependent ($8.6$, $p < 0.001$). Internalizing safety costs efficiency. The policy has to navigate around hazards rather than through them.
This is a genuine design decision:
- If the shield will always be present: dependency might be fine. The system works better. But test what happens if the shield degrades — safety drops as a cliff, not a slope.
- If the policy might need to operate independently: you need one of the three fixes. Accept the efficiency cost.
- Always evaluate raw-policy safety separately. A system that appears perfectly safe may contain a policy that is 50% unsafe. System-level metrics hide component-level fragility.
The broader pattern
The safety signal barrier may not be specific to RL shields. It suggests a broader principle: enforcement and learning are distinct objectives that can conflict.
When an external mechanism intercepts failures before the learner observes them, the learner never develops internal representations of the failure mode. Think about where else this might apply:
- Guardrails in language model fine-tuning — if a guardrail blocks harmful outputs during RLHF, does the base model learn to avoid them, or does it learn that guardrails exist?
- Automated correction in robotics — a safety layer that overrides dangerous motor commands may prevent the controller from learning which states are dangerous.
- Human oversight in interactive learning — if a human always catches mistakes before they matter, the system may never develop its own error detection.
In each case: does the safety mechanism teach the learner to be safe, or does it teach the learner that safety is someone else's problem?
The lesson from stability of safety is that staying safe under perturbation is hard. The lesson here is that getting the agent to want to stay safe — in a way that's robust to removing the training scaffolding — is a separate problem entirely.
Limitations
The positive results come from a family of 2D navigation tasks. The information barrier mechanism is general, but optimal parameters (dropout rate, auxiliary reward scale) likely require environment-specific tuning.
Each seed produces either a fully safe or fully unsafe policy — the outcome is bimodal with no intermediate values. More complex environments might yield graded safety outcomes that support richer analysis.
I haven't tested this on high-dimensional continuous control benchmarks beyond Hopper (Safety Gymnasium was incompatible with my software stack). The boundary between "shield dropout helps" and "it doesn't" — discrete hazard avoidance vs. continuous constraint satisfaction — deserves more exploration.
Paper: The Safety Signal Barrier in Shielded Reinforcement Learning (AAAI 2026 format, 7 pages)
Code: Reproduces on CPU. Confirmatory experiment ($n = 40$) takes ~8 hours. Multi-environment ($n = 12 \times 3 \times 5$) takes ~12 hours.
Written by Austin T. O'Quinn. If something here helped you or you think I got something wrong, I'd like to hear about it — oquinn.18@osu.edu.